Q Learning
阅读量:[object Object]
#播种
Q-Learning 是一个 异策(off-policy)基于价值的强化学习方法,使用 Temporal Difference 策略更新价值函数。是一种运用表格的方法。
缘由
[!note] 记录为什么有这个概念/想法/事实/观点,属于 why 的部分
说明
Q 指当前状态执行的动作质量(Quality),Q 函数使用 Q-table 来记录每个状态所对应动作的价值
- 初始化 Q-table,每个状态 - 动作的值初始化为 0
- 根据 Epsilon-Greedy Policy 选择将要执行的动作
- 执行动作
- 更新 Q-table,即更新
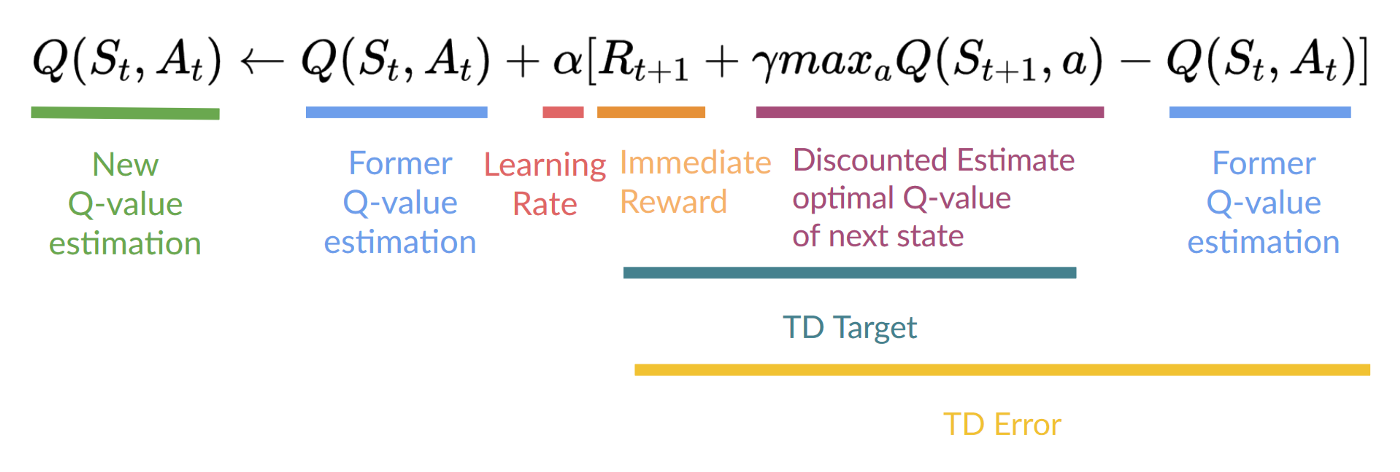
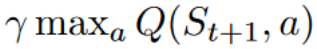
Q-Learning 的伪代码如下

实例
[!note] 记录概念的应用实例,属于 how 的部分
类比
[!note] 记录与该概念类似的概念,属于 how 的部分
对比
[!note] 记录与该概念进行对比的概念,属于 how 的部分
效果
[!note] 记录该概念如何解决实际问题,属于 how good 的部分
备注
[!note] 记录相关链接等其他补充内容
反向链接
到头儿啦~
预览: