Epsilon Greedy policy
阅读量:[object Object]
#播种
通常用来平衡探索/利用关系的策略,在 强化学习、推荐系统等领域中广泛应用
缘由
[!note] 记录为什么有这个概念/想法/事实/观点,属于 why 的部分
说明
将
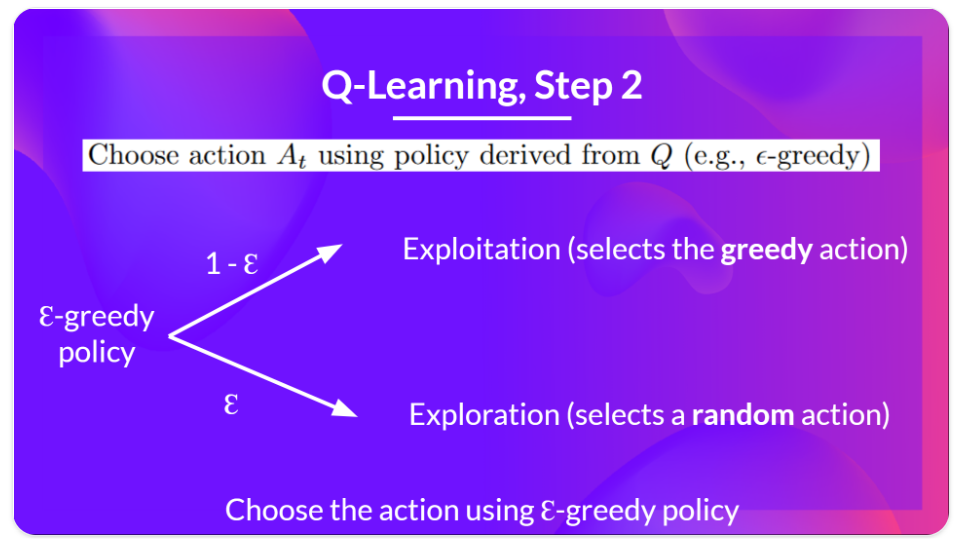
实例
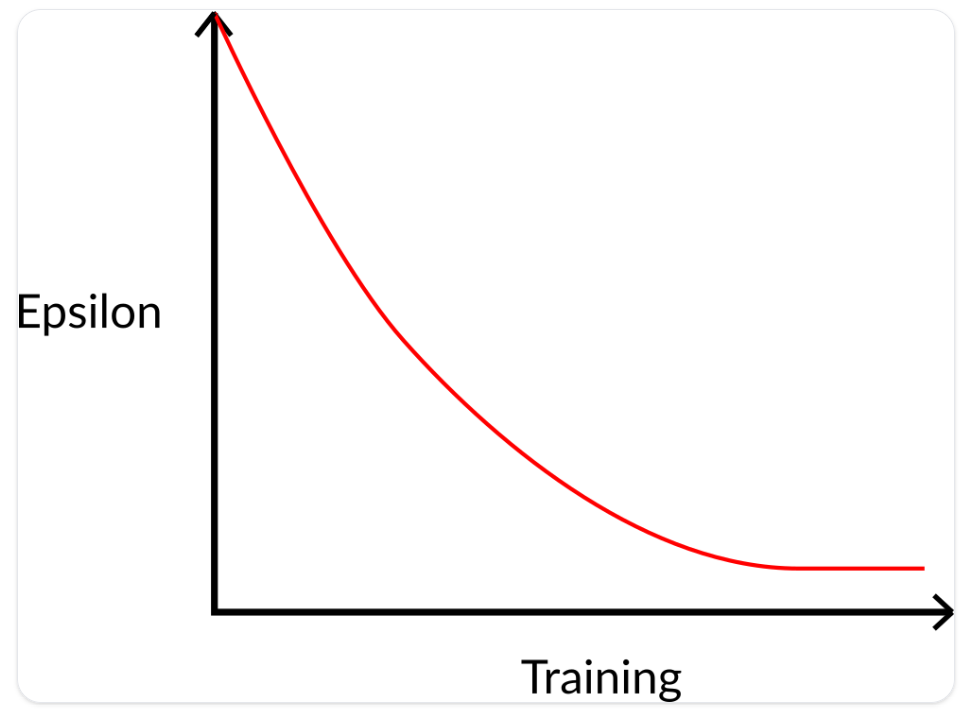
衰减方式
类比
[!note] 记录与该概念类似的概念,属于 how 的部分
对比
- [[ Greedy Policy ]]
效果
使得智能体在不同阶段选择探索/利用已有知识的比例,同时确保在学习后期仍然保持一定探索新的可能性的几率
备注
[!note] 记录相关链接等其他补充内容
反向链接
Rl value function 价值函数
强化学习中 [[Value-Based Method 基于价值的方法
Value-Based Method]] 所使用的价值函数(Value Function)
强化学习 q Learning 简介
Q-Learning 是强化学习中的一种 [[RL Off-policy and On-policy 异策和同策 异策]](off-policy)、无模型(model-free)算法,由 [[强化学习 - Q-Learning 简介#^56bb17 Watkins]] 在 1989 年提出。是用来求解 [[Markov Decision Process 马尔可夫决策过程...
到头儿啦~
预览: