Probability distribution 概率分布
阅读量:
概率分布(Probability Distribution)或简称分布,是 概率论 的一个概念。使用时可以有以下两种含义:
- 广义地,它指称随机变量的概率性质 – 当我们说概率空间
称
但是,不能认为同分布的随机变量是相同的随机变量。事实上即使
- 狭义地,它是指随机变量的概率分布函数。设
具有相同分布函数的随机变量一定是同分布的,因此可以用分布函数来描述一个分布,但更常用的描述手段是 概率密度函数(Probability Density Function, 简称 PDF)。
- 在常用的文献中,“分布”一词可指其广义和狭义,而“累计分布函数”或“分布函数”一词只能指称后者。
概率分布给出了所有取值及其对应的概率(少一个也不行),只对离散型变量有意义。例如:
针对连续型变量时,称作概率分布函数。
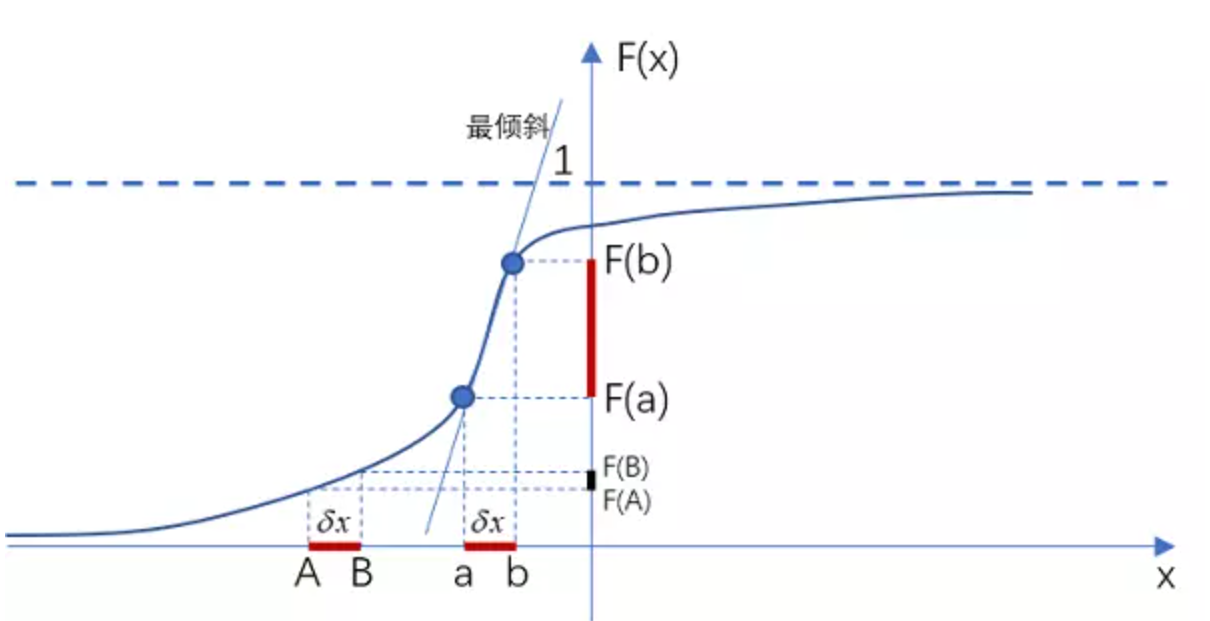
概率分布函数
概率分布函数 F(x) 的性质:
概率分布函数
-
给出
-
根据
#待整理笔记
反向链接
Estimation theory 估计理论
[!概述]
估计理论是 [[Statistics 统计学|统计学]] 和 信号处理 中的一个分支,主要是通过测量或经验数据来估计 [[Probability Distribution 概率分布|概率分布]] 的 参数 或某个系统的 [[状态变量]]。在现实中,我们通常只能观测到带有噪声或误差的数据,因此需要使用估计理论的方法来得到最优的估计。
Probability density function 概率密度函数
在 [[210 - Mathematics 数学
数学]] 中,连续型随机变量 的概率密度函数(Probability Density Function)(在不至于混淆时可以简称为密度函数)是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。图中,横轴为随机变量的取值,纵轴为概率密度函数的值,而随机变量的取值落在某个区域内的概率为概率密度函数在这个区域上的积分。当概率密度函数存在的时候,[[Probability Distribution 概率分布
累积分布函数]] 是概率密度函数的积分。概率密度函数一般以大写“PDF”(Probability Density Function)标记。
到头儿啦~
预览: