Policy Gradient method 策略梯度方法
阅读量:
RL 中一种 基于策略 的方法,使用 [[ 梯度上升法 ]] 对目标函数的参数进行直接优化。
WHY
WHAT

HOW

目标函数用于评价 agent 在给定的 trajectory(一系列行动)上的表现。



对目标函数进行变换,使其 [[ 可导 ]]。
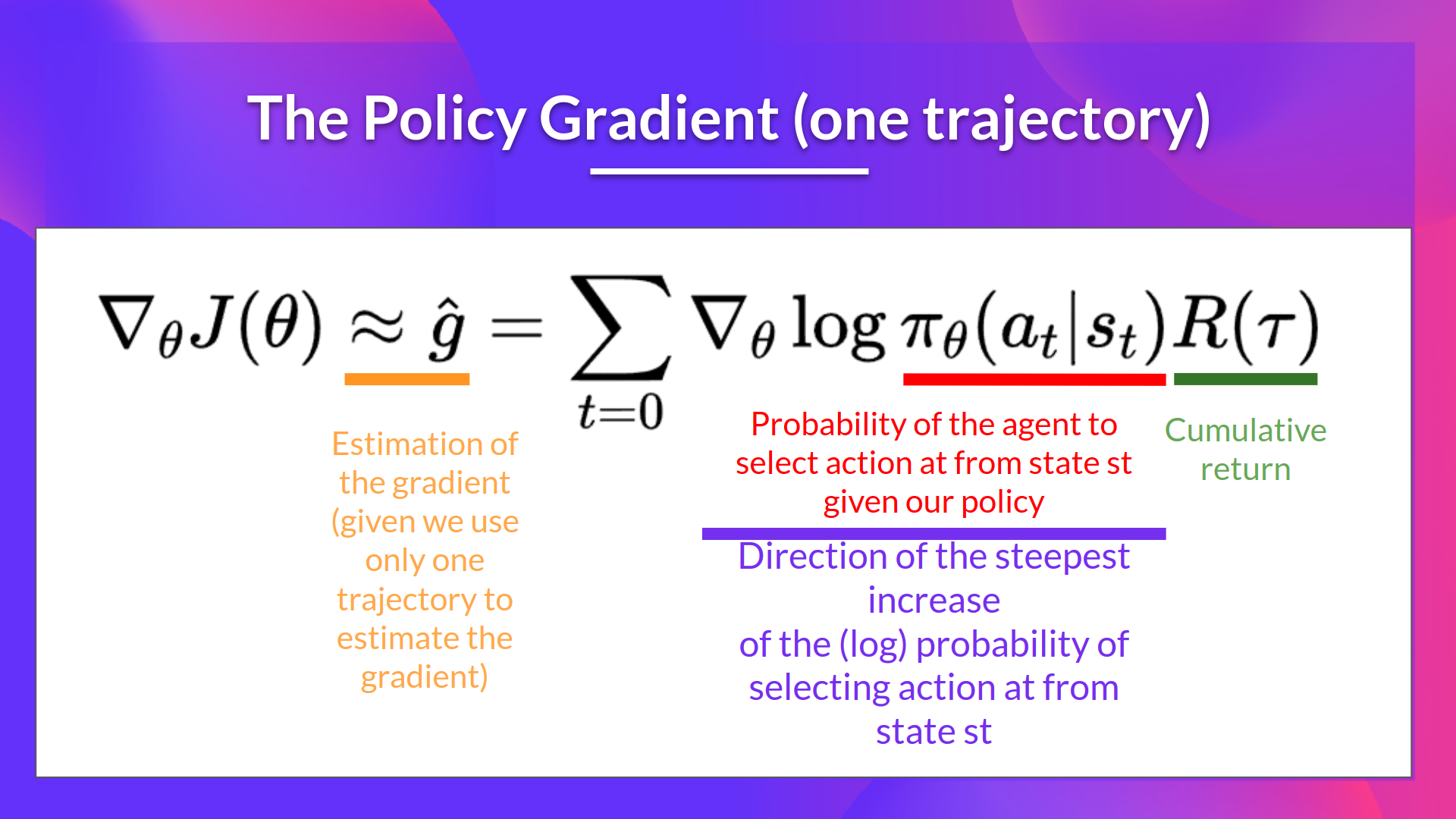
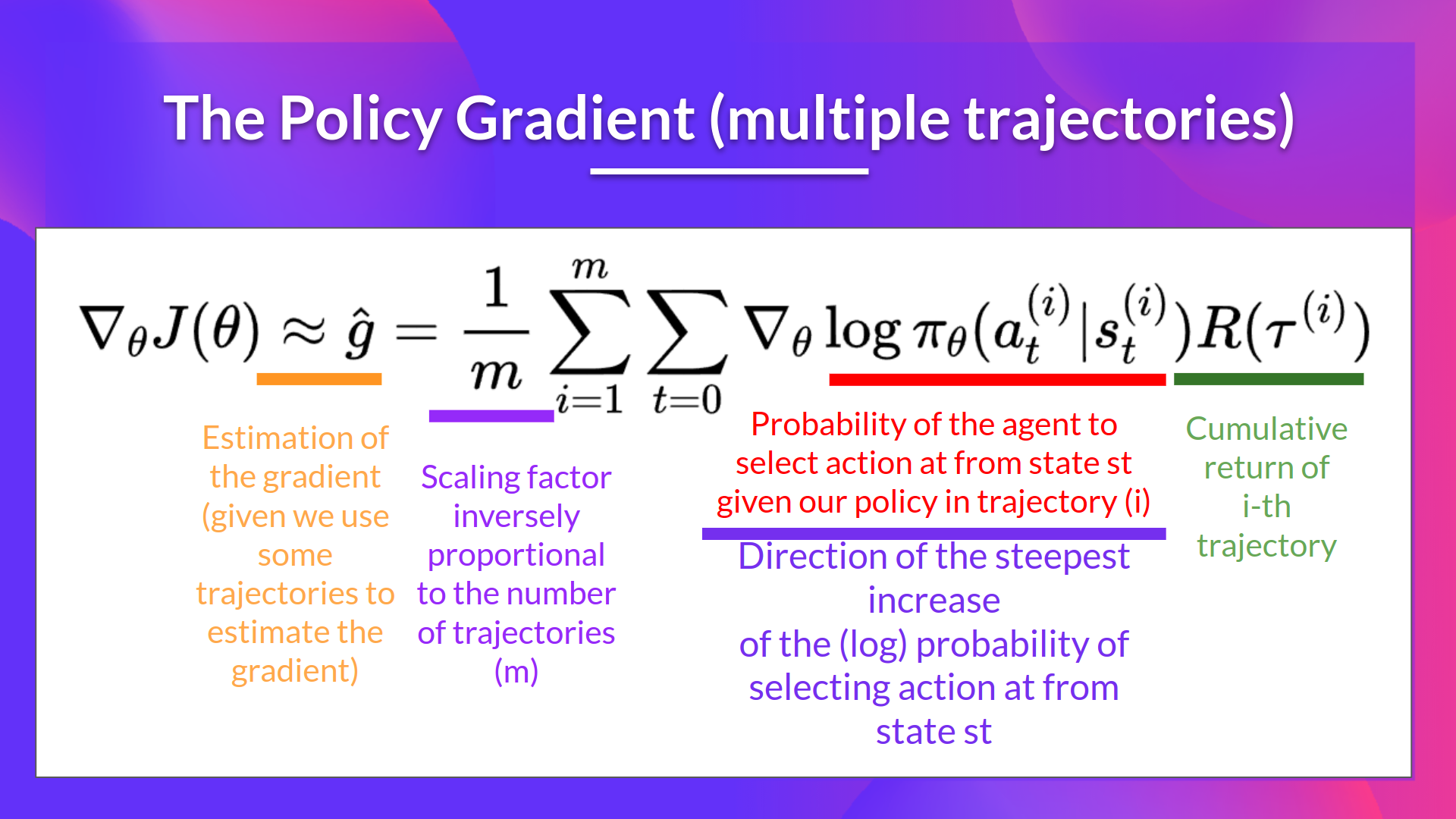
实例
HOW GOOD
优点:
- 直接对行动策略函数进行估计,不需要储存额外的信息(行动的价值)
- 能够学习随机的行动策略
- 针对高维度行动空间和连续的行动空间,策略梯度方法更有效率
- 策略梯度方法有更好的收敛性能
缺点
- 经常陷入局部最优解
- 策略梯度需要逐步求解,时间花费更高
- 可能会有很高的方差,用 [[ Actor-Critic ]] 方法来缓解
ref.
#待整理笔记
反向链接
到头儿啦~