Policy Based method 基于策略的方法
阅读量:
强化学习中的一种 行动策略,让 Agent 直接学习在给定状态下如何行动。
WHY
WHAT
策略函数(policy function)定义了一个在每个状态下最佳行动的映射。或者说,定义了在每个状态下一个可能的行动集的概率分布。
HOW
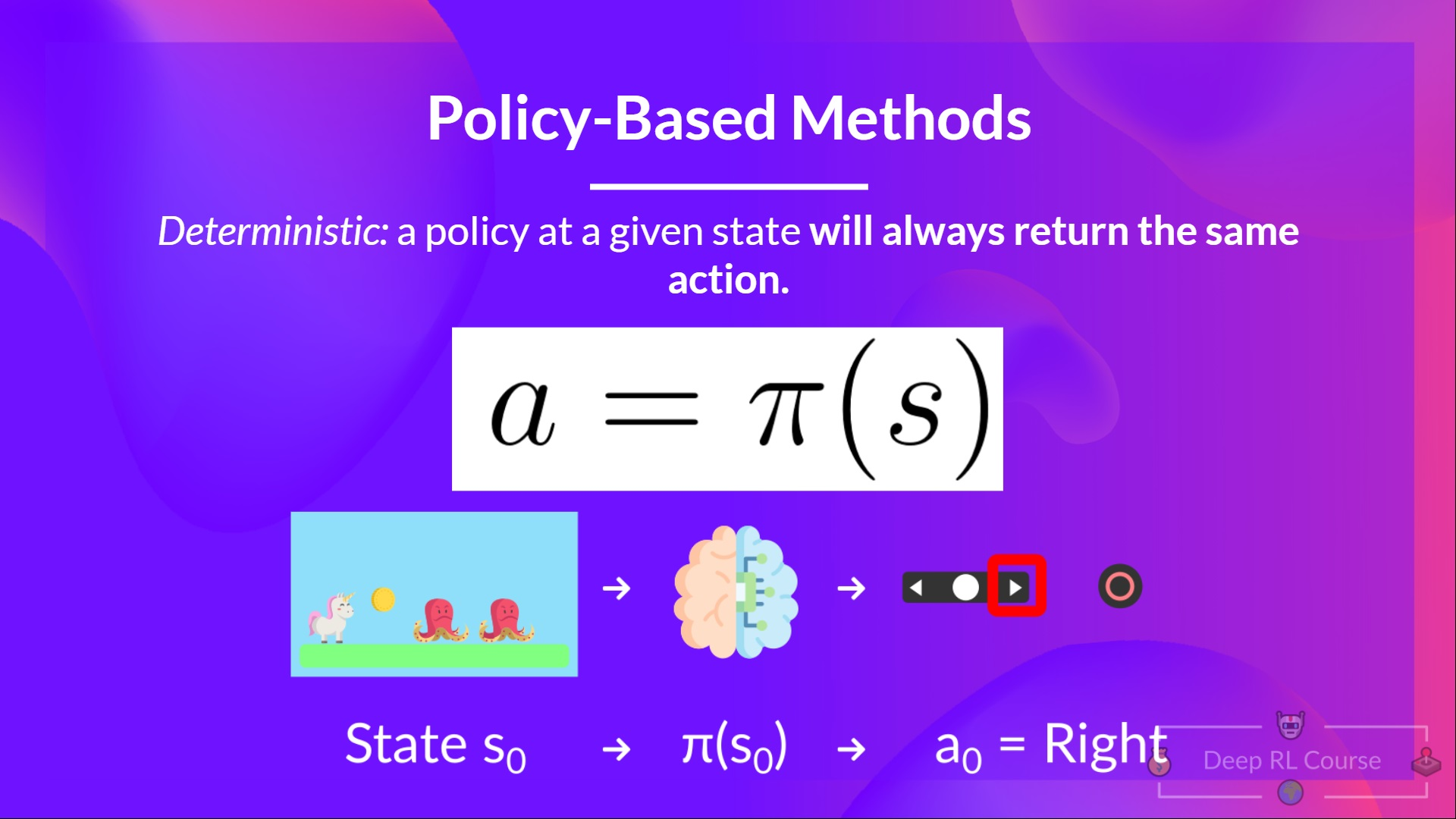
有两种策略:确定性(Deterministic)和随机性(Stochastic)。
确定性(Deterministic):对于给定的状态,总是输出一个相同的行动。
随机性(Stochastic):输出一个行动集的概率分布。

实例
HOW GOOD
ref.
#待整理笔记
反向链接
Policy Gradient method 策略梯度方法
RL 中一种 [[Policy-Based Method 基于策略的方法
基于策略]] 的方法,使用 [[梯度上升法]] 对目标函数的参数进行直接优化。
到头儿啦~